好久没写过博客了,其实由于暑期实习能写的素材还是有的,但是由于自己可能要准备考研,所以也那么多时间来做这些,不过最近在准备保研面试,所以又回看计算机的基础,看到了KMP算法,因此来简单写篇博客来记录一下,如果保研之路顺利的话,以后应该会经常写博客了,要是考研的话,估计要很久写不了了.
前言
KMP算法其实阮一峰老师已经写过相关的文章了,因此我也并不准备从头来写,打算主要借鉴一下他的文章,相当于搬运一下吧,顺便加深一下自己的印象,免得看过就忘.这是原博客地址:字符串匹配的KMP算法-阮一峰日志
普通的字符串匹配算法
普通的字符串匹配算法是明显低效的, 由于每一次匹配失败都会导致回滚到上次匹配成功的第一个字母的后面一个字母, 因此是浪费了时间的, 这样说可能不容易理解, 举个例子来看, 比如现在有字符串AAAAHAAAHAHAHA, 我们想找找HAHAHA是否存在与前面的字符串中, 当我们比较到第五个字符串的时候, 是匹配的,即H, 然后匹配下一个字符A, 发现也是匹配的, 继续, 发现原字符串的下一个字符是A, 但是我们期望的是H, 因此匹配失败, 这个时候普通的匹配算法会从第六个字符开始匹配, 也就是A, 这个时候肯定是匹配失败的, 实际上我们直观上来看就是很笨的行为, 我不太好形容, 但是因为我们已经成功匹配了2个字符, 即我们已经知道了原字符串中H下一个字符是A了, 我们想要匹配的字符第一个字符是H, 所以这样匹配明显是会失败的, 也就是说这点会导致我们的时间复杂度增加, 这也就是KMP算法改进的地方吧.
KMP算法
我将主要流程贴点图吧, 具体就不细说, 其实理解起来不太难

下一步

直到匹配到第一个字符

向后匹配

找到第一个不匹配的,需要重新开始匹配,这个时候就像我们在上面说的, 肯定不是直接向后移动1位开始匹配, 但是需要移动多少位呢, 这就是KMP算法会告诉我们的
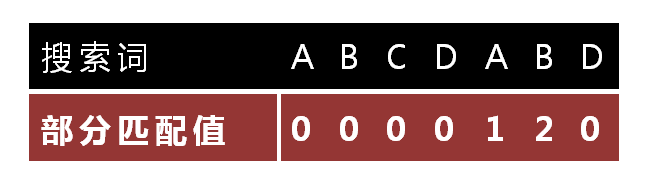
先不管这个表怎么算的, 我们先用着, 后面会有解释
计算移动位数的公式是:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
在这里已匹配的字符数是6, 最后一个匹配的字符的部分匹配值查表为2, 故移动位数为4 = 6 - 2
所以我们就跳到第8位开始继续匹配, 如下图

重复上面的过程, 直到找到

如果要继续搜索, 就向后移动7位 = 7 - 0, 注意这里的7位不是字符串的长度, 是通过KMP算法计算出来的.
部分匹配表的计算
首先,要了解两个概念:”前缀”和”后缀”。 “前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例:
- “A”的前缀和后缀都为空集,共有元素的长度为0;
- “AB”的前缀为[A],后缀为[B],共有元素的长度为0;
- “ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- “ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- “ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为1;
- “ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,长度为2;
- “ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
上面也就是部分匹配表的由来:
部分匹配的实质就是因为字符串内部的重复, 很好理解, 相信大家稍微动下脑筋都能看出来.